Abstract
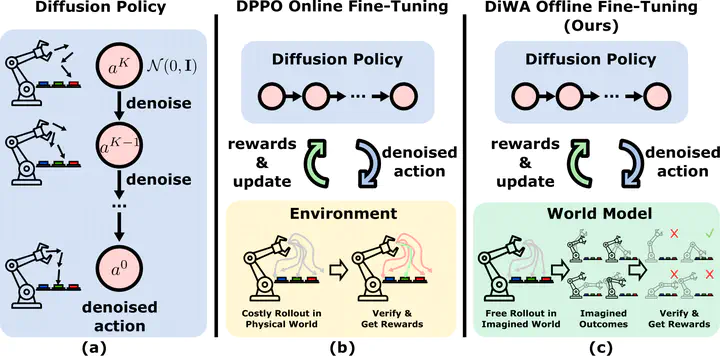
Fine-tuning diffusion policies with reinforcement learning (RL) presents significant challenges. The long denoising sequence for each action prediction impedes effective reward propagation. Moreover, standard RL methods require millions of real-world interactions, posing a major bottleneck for practical fine-tuning. Although prior work frames the denoising process in diffusion policies as a Markov Decision Process to enable RL-based updates, its strong dependence on environment interaction remains highly inefficient. To bridge this gap, we introduce DiWA, a novel framework that leverages a world model for fine-tuning diffusion-based robotic skills entirely offline with reinforcement learning. Unlike model-free approaches that require millions of environment interactions to fine-tune a repertoire of robot skills, DiWA achieves effective adaptation using a world model trained once on a few hundred thousand offline play interactions. This results in dramatically improved sample efficiency, making the approach significantly more practical and safer for real-world robot learning. On the challenging CALVIN benchmark, DiWA improves performance across eight tasks using only offline adaptation, while requiring orders of magnitude fewer physical interactions than model-free baselines. To our knowledge, this is the first demonstration of fine-tuning diffusion policies for real-world robotic skills using an offline world model. We make the code publicly available at https://diwa.cs.uni-freiburg.de.
Iman Nematollahi*
Postdoc in Robot Learning & AI for Oncology
My research interests include deep learning, world models, and reinforcement learning.