Abstract
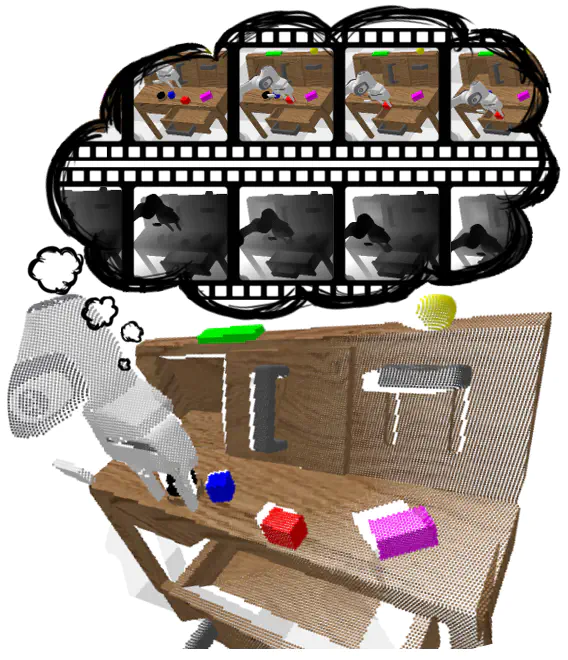
For autonomous skill acquisition, robots have to learn about the physical rules governing the 3D world dynamics from their own past experience to predict and reason about plausible future outcomes. To this end, we propose a transformation-based 3D video prediction (T3VIP) approach that explicitly models the 3D motion by decomposing a scene into its object parts and predicting their corresponding rigid transformations. Our model is fully unsupervised, captures the stochastic nature of the real world, and the observational cues in image and point cloud domains constitute its learning signals. To fully leverage all the 2D and 3D observational signals, we equip our model with automatic hyperparameter optimization (HPO) to interpret the best way of learning from them. To the best of our knowledge, our model is the first generative model that provides an RGB-D video prediction of the future for a static camera. Our extensive evaluation with simulated and real-world datasets demonstrates that our formulation leads to interpretable 3D models that predict future depth videos while achieving on-par performance with 2D models on RGB video prediction. Moreover, we demonstrate that our model outperforms 2D baselines on visuomotor control. Videos, code, dataset, and pre-trained models are available at http://t3vip.cs.uni-freiburg.de.
Iman Nematollahi
Postdoc in Robot Learning & AI for Oncology
My research interests include deep learning, world models, and reinforcement learning.